从文件读取数据
函数tf.train.string_input_producer文件名队列,选择一个匹配输入文件的reader,reader从filename queue中选择文件读取,每次输出一个key, value对。再由一个合适的decoder解析value,这样可以把value中的各个字段解析出来。通过解析出来的字段,组成tensor作为输入数据,送到graph中去train或predict。
疑问:这里为啥要把filename做成一个队列呢?reader每次read一个文件一行,下次是从第二行开始么?
整个读文件的过程分为建文件队列、建立reader、建立decoder、形成tensor,把文件读取的过程分的特别细致。除了 tf.TextLineReader还有支持二进制和TF Record的reader。
得到数据以后,可以在开始train之前,进行必要的数据预处理,正则化,或者加噪音等等。
数据打包(batch)
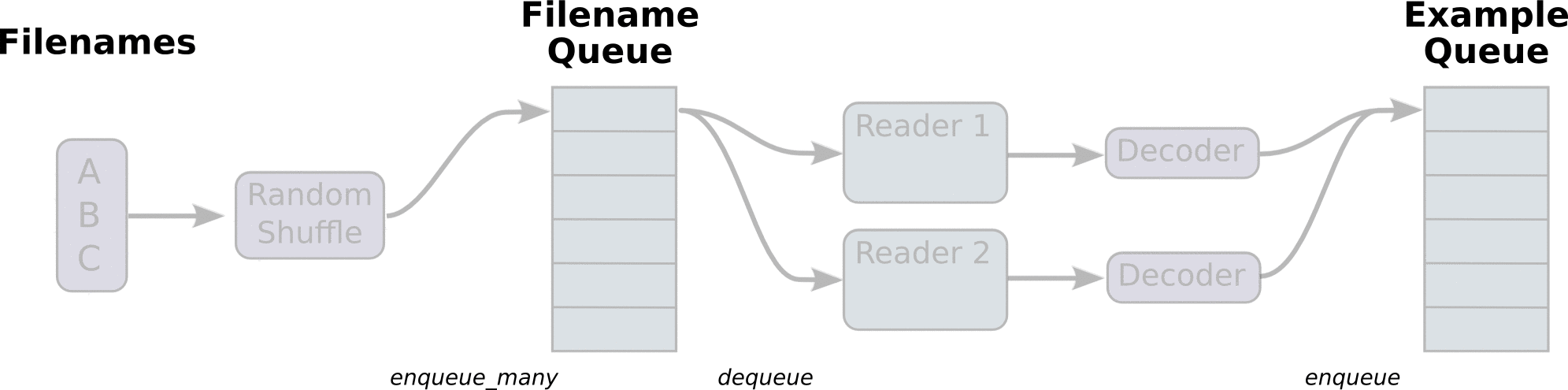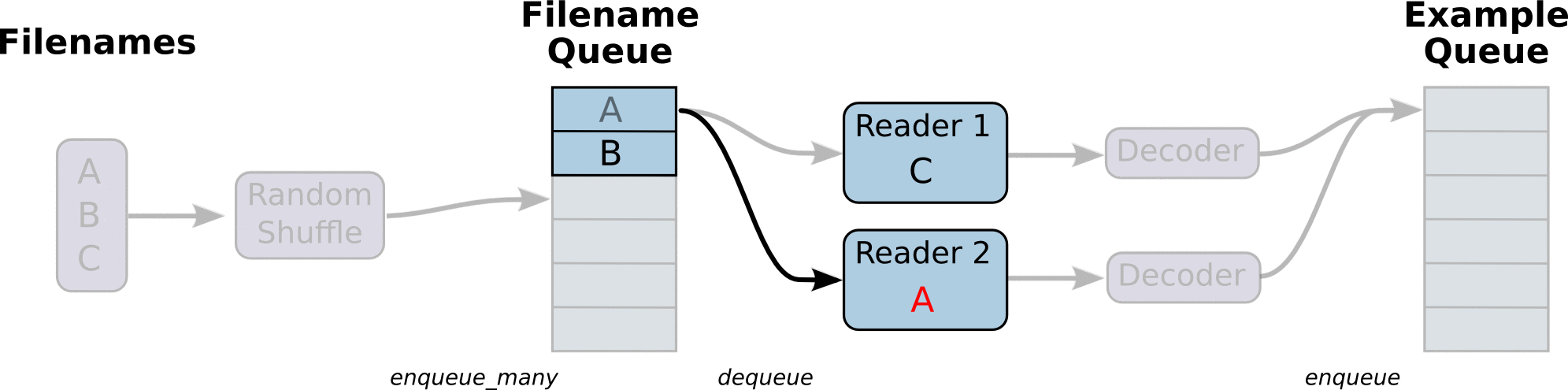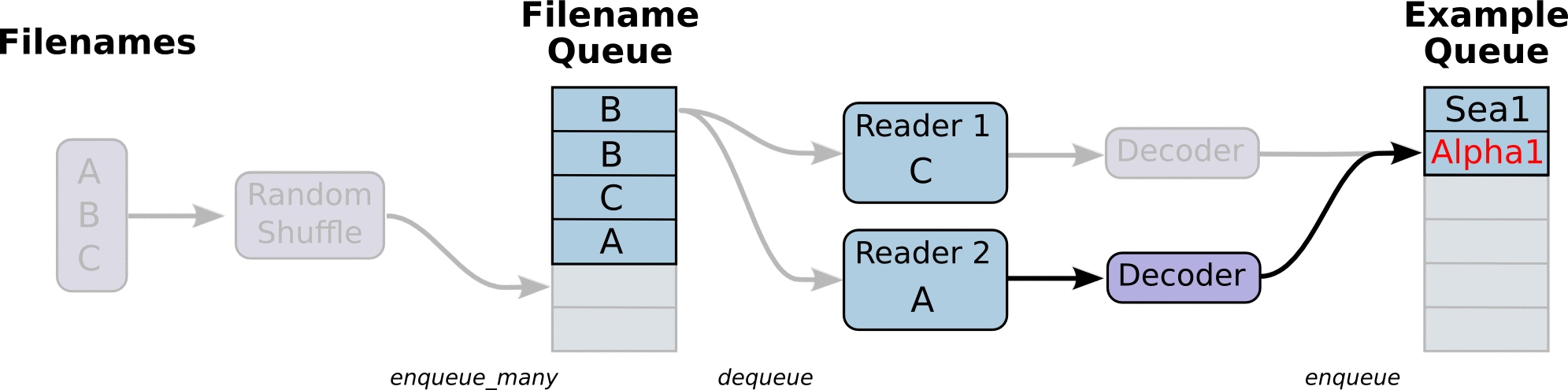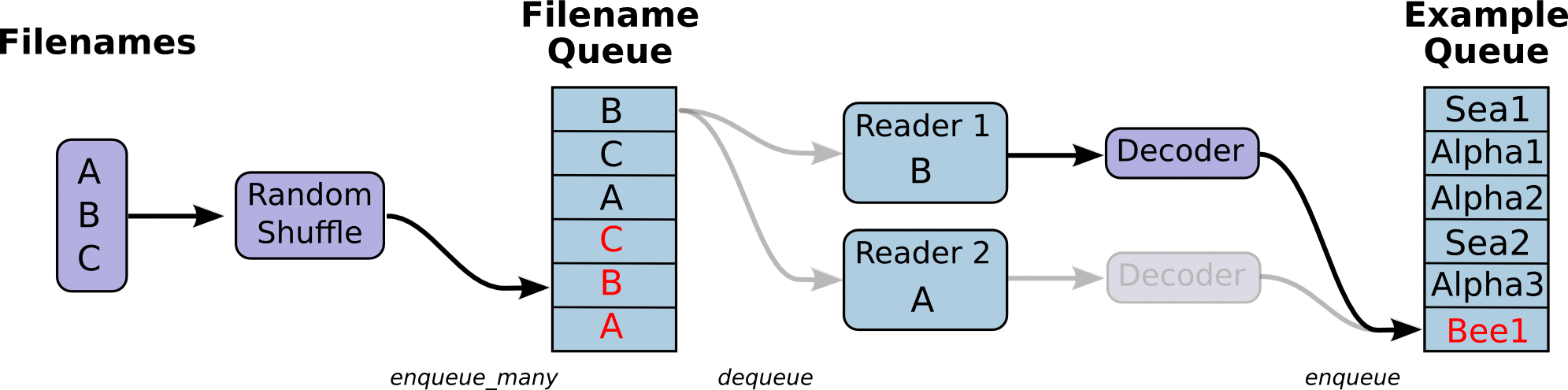
reader读出来的数据,再放到一个队列中,凑够一批再传给graph计算,这样会高效很多。不明白为啥要把流程搞得这么复杂,仅仅是读数据,却要两个队列,N个线程,N2 个函数来配合。而且结束的时候,也需要通过exception的方式来判断,并且要等所有线程都停止了,才能结束。感觉好麻烦啊。
似乎想明白一点,其实就是说整个train的过程,并不关心数据从哪里来,怎么来的,他只是调用一个input_fn(),然后就得到一批数据,就可以进行计算了。这些数据实际上是多个线程放入到一个数据队列中的,这些线程其实也不关心这些数据怎么用,谁会用,他们只是按照一定规则把数据入队,就算完成任务了。